This term, I’m a teaching assistant for BME 121: Digital Computation. My role for this course, beyond office hours and assignment marking, has been making lab prep videos. Instead of tutorials this term, these lab prep videos are meant to provide the students with some coding examples that can hopefully help them with the lab activities.
Convolutional neural networks (CNNs) have had much success in achieving state of the art results in various machine learning tasks.
Their success is largely due to the high number of parameters that allow for the approximation of complex functions.
The overparameterization of CNNs results in networks that are very large and have a high computational cost, measured by FLOPS (floating point operations per second).
When running a CNN on a resource-constrained edge device, the size of the network needs to be minimized while maintaining a high performance.
Butterfly matrices have been proposed as a method for improving the computational complexity of machine learning tasks.
In this paper, three methods that use butterfly matrices will be explored.
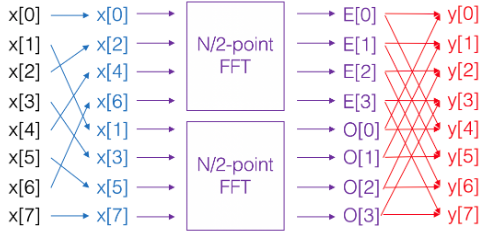
The butterfly matrix is mostly known from its use in the Cooley-Tukey fast Fourier transform (FFT) algorithm.
It is used to recursively break down a discrete Fourier transform into smaller transforms and recombines them with several butterfly transforms (Figure 1).
Figure 1: Fast Fourier transform for N = 8 data points. FFT breaks down into two DFTs and recombines with butterfly operations.
The recursive nature of the factorization gives a series of matrices with a sparcity pattern. These matrices are called butterfly factors.
In this report, butterfly matrices are applied to deep learning to improve efficiency and accuracy.
The butterfly transform can be used to replace pointwise convolution and achieve better performance.
In addition, butterfly matrices are used to learn linear transforms and function representation.
The Butterfly Transform
Alizadeh, Farhadi and Rastegari have proposed the Butterfly Transform (BFT) that reduces the complexity of 1D convolution during channel fusion in CNNs. It has also been shown to increase the accuracy of the CNNs with FLOPS values.
To avoid overparameterization of CNNs and reduce their computational complexity, current efficient architectures factorize the convolutional layers using separable, depth-wise convolution. This means that convolution is performed separately in two components: spatial fusion and channel fusion. In channel fusion, the channels are linearly combined with point-wise (1 \( \times \) 1) convolutions. These operations are relatively more computationally expensive than the channel fusion operations. It has been found that channel fusion has \( \mathcal{O}(n^2) \) complexity, where \( n \) is the number of channels.
Point-wise convolutions can be represented by matrix multiplication, which can be optimized by imposing structure on the transformation matrix. The authors prove that using an ideal transformation matrix has at least \( \mathcal{O}(n \log{} n) \) complexity. They propose a butterfly matrix as this ideal transformation matrix for spatial fusion.
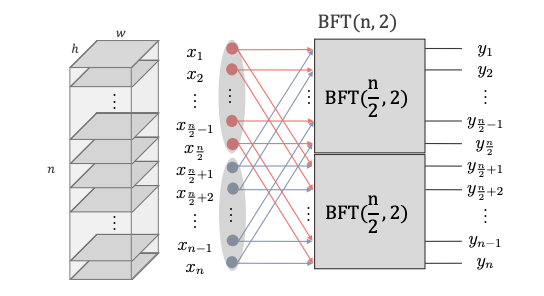
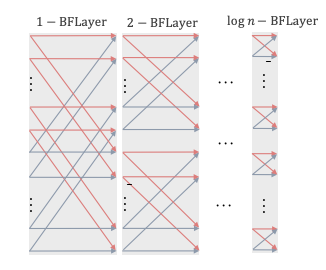
Multiplication of a butterfly matrix and a vector recursively calculates the product with a divide-and-conquer approach. Figure 2 shows the BFT with \( k = 2 \) and Figure 3 shows the recursive nature of the transform with \( \log{} n \) butterfly layers.
Figure 2: Butterfly transform architecture with k = 2.Figure 3: Expanded butterfly transform architecture with log n butterfly layers.
The complexity of each butterfly layer is \( \mathcal{O}(n) \), thereby giving the architecture \( \mathcal{O}(n \log{} n) \) complexity. The butterfly network is an ideal fusion network, as it has one path between every input channel to all output channels (every-to-all connectivity), the bottleneck size is a maximum (size \( n \), the number of edges is a minimum (\( \mathcal{O}(n \log{} n) \) edges), and all nodes within a layer have the same degree.
To test the network, the authors replaced the point-wise convolution layers in several CNN architectures to determine effects on computational complexity and accuracy. First, image classification with MobileNet and ShuffleNet on ImageNet were tested. To ensure fair testing, the authors adjust the number of channels in the architecture to have the same number of FLOPS.
Replacing pointwise convolutions with BFT in MobileNetV1 results in an increase in top-1 accuracy at the same complexity. In addition, accuracies were compared between MobileNet and MobileNet + BFT at increasing FLOPS. It was found that MobileNet + BFT at 14 MFLOPS can achieve slightly higher performance as MobileNet at 21 MFLOPS. Similar results were reported with ShuffleNetV2.
The authors also compared performance of ShuffleNetV2 + BFT with state-of-the-art architecture search methods MNasNet and FBNet at an efficient network setting. They suggest including BFT as a searchable block in these models.
Finally, accuracy was higher with MobileNet + BFT than with MobileNet with other \( \mathcal{O}(n \log{} n) \) architectures for pointwise convolution (MobileNet + Circular and MobileNet + Low-Rank Matrix).
In the ablation studies, the effects of adding a non-linearity to the BFT layers were observed. Adding ReLU and sigmoid activation functions significantly reduces accuracy because some neurons will be assigned a value of zero, which cuts off information flow from the input to the output. Adding weight decay is also destructive as it also pushes weights to zero. Since the BFT network has only one path from the input to the output, these two methods significatly drop accuracy. Finally, it was found that adding residual connections within the BFT block increases accuracy. The BFT graphs can become deep, and accuracy is increased the most when the input of the first butterfly layer is connected to the last butterfly layer.
BFT has been proposed as a more efficient alternative for pointwise convolution. They also acknowledge that more gains are obtained with smaller networks than large ones. Since FFT is a common operation, optimized hardware platforms exist that can further speed up BFT.
Butterfly Factorizations
An application of butterfly matrices in machine learning was explored by Dao et al. They describe butterfly parameterization, a method for learning structured efficient linear transforms, rather than having to handcraft them. These transforms include FFT, discrete cosine transform and Hadamard transform.
Many discrete linear transforms can be represented as a product of sparse matrices that together model a recursive function. The butterfly factorization can be used for neural network compression, whereby fully connected layers are replaced by low rank maps. In this work, the \( 1 \times 1 \) layers in MobileNet are also replaced by butterfly matrices. They also achieve higher accuracy with fewer parameters on the CIFAR-10 dataset.
Butterfly-Net
Chang, Li and Lu propose a network architecture to perform function representation in the frequency domain based on the discrete Fourier transform, which uses butterfly matrices. It has a similar accuracy to CNNs, but with fewer parameters and more robustness.
Conclusions
Butterfly matrices, inspired by their use in the Cooley-Tukey FFT, have been proposed as a way to increase computational efficiency and accuracy in deep neural networks while performing matrix multiplication.
In an image classification problem, replacing pointwise convolution with the butterfly transform in MobileNet and ShuffleNet gives higher accuracy with reduced FLOPS. Higher accuracy is also obtained than using efficient architecture search networks.
In addition, butterfly matrices can be used for learning linear transforms and function representations.
Using butterfly matrices in deep neural networks appears to be a promising area for further research. Due to the popularity of the FFT algorithm, there exists software and hardware that can further accelerate butterfly algorithms.